Couchbase — это документо-ориентированная база данных (не путать с CouchDB и Membase!), интересная своей относительной простотой, исключительной легкостью в настройке и поддержке, высокой скоростью выполнения запросов за счет размещения «горячих» данных в памяти, масштабируемостью, а также автоматическим восстановлением кластера в случае падения машин и рядом других моментов. Например, поддержкой вторичных индексов, вьюх, репликации между дата-центрами (XDCR, как master-slave, так и master-master), обратной совместимостью с Memcached и не только. Написано все это на С/C++ и Erlang . Couchbase используется в AOL, Cisco, LinkedIn и множестве других компаний .
Немного теории
В двух словах о том, как работает Couchbase. Строго говоря, Couchbase является больше key-value базой данных, чем документо-ориентированной. Вся документо-ориентированность сосредоточена в клиентском API (есть библиотеки для Java, Си, .NET, Node.js, PHP, Python, Ruby, и других языков ), а также возможности сервера пропарсить сохраненные значения для построения вторичных индексов и вьюх. Аналогом отдельной базы данных из мира РСУБД в Cocuhbase является бакет. Есть подозрения, что бакеты также можно использовать в качестве своего рода аналога таблиц, но официальная документация по Couchbase не рекомендует создавать более десяти бакетов. Бакеты бывают двух видов — Memcached-бакеты и Couchbase-бакеты.
Memcached-бакеты хранят все данные только в памяти и предназначены для кэшей и прочих данных, которые не страшно потерять. Couchbase-бакеты держат данные на диске. «Горячие» данные при этом кэшируются в памяти по принципу LRU . Используется собственная реализация кэша, не системный mmap . Плюс к этому Couchbase-бакеты могут реплицироваться на другие ноды. Один бакет может иметь от 1 до 3 реплик. Клиентские библиотеки поддерживают чтение как с мастера, так и с реплик.
Данные в Couchbase распределяются между узлами кластера равномерно. Для этого используются так называемые vBucket’ы, число которых задается при создании кластера и по-умолчанию равно 1024. Каждый узел в кластере является мастером или репликой определенных vBucket’ов. При чтении или записи документа, считается хэш от ключа. По этому хэшу определяется номер vBucket’а. Затем клиент по таблице, полученной от узлов кластера, смотрит, какие узлы в данный момент отвечают за этот vBucket, и обращается к ним. Через веб-админку можно запустить ребалансировку. В этом случае vBucket’ы будут перераспределены по кластеру, а клиенты, если во время ребалансировки они обратятся за документом не к тем узлам, будут перенаправлены на верные узлы.
В случае падения узлов кластера, переполнения дисков и других проблем, Couchbase отправляет письмо на указанные e-mail. По метрикам и логам, доступных в админке, можно диагностировать проблему. При падении одного из узлов, можно нажатием одной кнопки для vBucket’ов, оставшихся без мастера, выбрать нового мастера среди реплик, которые все еще доступны. Кроме того, поддерживается функция автоматического фейловера.
Надо отметить, Couchbase производит впечатление очень правильной БД, потому что:
- Он не хуже Memcached , так как полностью поддерживает его протокол, умеет хранить значения размером до 20 Мб (только в Couchbase бакетах, в Memcached бакетах — до 1 Мб) и более предсказуемо ведет себя в граничных случаях вроде добавления узлов в кластер;
- Он не хуже Redis , так как может хранить данных больше, чем помещается в память, а также поддерживает автофейловер;
- Он не хуже MongoDB , поскольку до безобразия прост в настройке и поддержке, и к тому же использует память только под действительно полезные данные, а не все, что лежало поблизости с «горячим» документом, как в случае с mmap;
Теперь, когда вы, надеюсь, заинтересованы, давайте перейдем к практике.
Установка и настройка Couchbase
Создадим в Амазоне Couchbase-кластер. В EC2 жмем Lauch Instance. Несмотря на то, что официальная документация Couchbase рекомендует использовать более мощные машины, на практике выяснилось, что система неплохо работает и на инстансах m3.medium с одним vCPU и 3.75 Гб оперативки. Размер жесткого диска я увеличил до 16 Гб. На шаге 3 в «Number of instances» указываем тройку. Три ноды минимум требуется для правильной работы автофейловера. Иначе при падении машины вы получите такое неприятное уведомление:
you need at least 2 other nodes.
В настройках Security Group создаем новую группу с такими правилами:
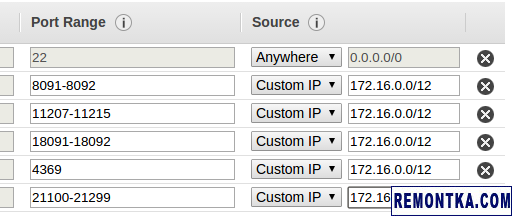
Здесь мы разрешили хождение на SSH откуда угодно (вам может захотеться это изменить!), а на используемые Couchbase’ом порты — только внутри нашей VPC. Админка при этом крутится на порту 8091 и защищена паролем. Если очень сильно хочется, то можно настроить Nginx с TLS и пробрасывать к этой админке доступ, но эта тема выходит за рамки данного поста.
После создания машин выяснилось, что своп на них выключен. Это хорошо. Проверьте командой swapon -s , что у вас он тоже выключен. Если включен, своп нужно обязательно отключить — см этот пост , пункт 3.
Далее здесь получаем ссылку для скачивания deb-пакета (придет на почту), качаем wget’ом и устанавливаем на всех трех машинах. Заходим в админку на первой машине. Поскольку порт админки закрыт, делаем так:
… и попадаем в админку через localhost:3333. Создаем новый кластер:

В поле Hostname указываем private ip инстанса. Квоту по памяти я указал 3011 Мб из 3764 Мб доступных. Couchbase не позволяет использовать больше 80% от всей памяти в системе. Далее нам предложат создать тестовые наборы данных, отказываемся.
Затем создаем Memcached-бакет, скажем, размером 1 Гб. Обратите внимание, что это количество памяти будет выделено под бакет на каждой ноде. То есть, если у вас сейчас три ноды, всего под бакет в кластере будет выделено 3 Гб памяти. Если потом вы добавите еще ноду — то 4 Гб. Притом никого как бы не волнует, что ноды бывают немного разными. Учтите также, что квоту по памяти после создания можно изменить только у Couchbase бакетов, но не у Memcached бакетов!
Присоединяем вторую и третью ноду к кластеру. Заходим в админку аналогично тому, как делали это раньше. Теперь вместо «Start a new cluster» выбираем «Join a cluster now». После подключения всех нод идем во вкладку Server Nodes и жмем Rebalance.
Далее Settings → Auto-Failover → Enable auto-failover. Хорошим таймаутом, согласно документации, является 30 секунд. Если в вашем кластере раз в год ломается одна машина, с таким таймаутом вы получите «6 девяток», что должно быть за глаза практически любому проекту. Ставить таймаут меньше не имеет значения, так как вы получите те же «6 девяток», но с б о льшей вероятностью ложного срабатывания автофейловера.
Еще можно настроить Alerts, посылая почту через Amazon SES. Этот шаг довольно тривиален, так как SES предоставляет обычный SMTP , поэтому не будем останавливаться на нем подробно.
Собственно, это все, установка предельно проста! Развернуть и протестить кластер можно буквально за считанные минуты. Встроенный просмотр документов, метрики и мониторинг просто прекрасны, никаких Datadog’ов и Logentries’ов локально держать не нужно. Просто поставил и работает.
Проверим работу кластера можно на нашем Memcached бакете. На порту 11211 в Couchbase крутится прокся под названием Moxi. В нее можно ходить по протоколу Memcached, а прокся определит, на каком узле хранится значение, и перенаправит запрос туда. В отличие от работы с Couchbase через специальный клиент, использование прокси приводит в дополнительным раундтрипам между хостами. Поэтому по возможности хождения через Moxi следует избегать. Но нам сейчас хочется просто поставить небольшой эксперимент, так что не страшно.
Пишем ключ:
set mykey 0 3600 5
12345
STORED
quit
Проверяем что ключ на месте:
get mykey
VALUE mykey 0 5
12345
END
quit
Можете повторить эксперимент, заведя Couchbase бакеты, а также проверить работу автофейловера. Согласно моим опытам, работает он просто отлично, главное не забыть настроить у бакета хотя бы одну реплику.
После окончательной настройки всех бакетов, квот, параметров репликации и так далее, обязательно сделайте ребалансировку, иначе в случае фейловера можно потерять часть данных.
Что остается за кадром
В отношении фичей Couhbase также справедливо следующее:
- Поддерживается операция Flush. Она полностью удаляет содержимое бакета. По умолчанию Flush выключен. Включить его для заданного бакета можно в админке. Разработчики Couchbase категорически не рекомендуют использовать Flush для чего-либо, помимо очистки тестового окружения;
- По умолчанию операция записи считается успешной, как только сервер обновил значение в памяти. Сохранение на диск и репликация происходят в фоне. Если сервер сразу после записи быстро ребутнется, данные вы потеряете. Если запишет на диск, но тут же на него упадет метеорит, прежде, чем произойдет репликация, то данные вы тоже потеряете. Клиентский API с помощью специальных флагов позволяет убедиться, что сделана запись на диск и/или произошла репликация на заданное количество нод прежде, чем запрос считается успешным;
- У Memcached бакетов нет реплик, а следовательно и автофейловера. При падении машин часть данных в Memcached бакетах просто теряется;
- Couchbase поддерживает значения-счетчики с атомарным увеличением и уменьшением на заданное число. Эти счетчики не могут быть отрицательными;
- Есть CAS, а также пессимистичные локи, которые на самом деле представляют собой тот же CAS, только еще и запрещают доступ к документу другим пользователям. Если за указанный таймаут, до 30 секунд, документ не будет изменен, блокировка автоматически снимается;
- У значений может быть TTL, а также, помимо операции set, этот TTL можно изменить операциями touch и getAndTouch;
- Поддерживаются bulk-операции, позволяющие прочитать или изменить множество документов за одно хождение по сети;
- Кроме того, есть операции append и prepand, атомарно дописывающие кусок данных в конец или начало документа;
- Операция observe позволяет подписаться метаинформацию документа. Например, можно узнать, когда документ будет сохранен на диск или среплицирован на заданное число нод;
- Couchbase умеет строить вьюхи, вычисляемые из оригинальных данных скриптами на JavaScript по принципу MapReduce. С их помощью можно строить индексы, в том числе и геопространственные . С этими вьюхами связан ряд ограничений. Они медленные, так как целиком лежат на диске. Они могут отставать от реальных данных. В них могут встречаться удаленные данные, а также данные с истекшим TTL;
- В developer preview находится интерфейс N1QL (произносится «никель»), представляющий собой что-то вроде SQL-интерфейса для Couchbase. N1QL позволяет частично обновлять и считывать JSON-документы, работать с бакетом, как с одной большой таблицей в РСУБД, а также строить индексы, реализованные поверх упомянутых выше eventual consistent вьюх;
- Репликация между ДЦ (XDCR) может быть односторонней, двусторонней и вообще любой. Вы просто говорите «реплицировать кластер А в кластер Б». С помощью этого примитива можно получить любую, сколь угодно сложную, топологию. Конфликты разрешаются в пользу более молодого документа, где молодость определяется по номеру ревизии, счетчику CAS, а также TTL. За счет последнего, например, реплицируется эффект от операции touch;
- Существует Couchbase Lite, встраиваемая версия Couchbase для iOS и Android. Lite версия способна синхронизироваться с подмножеством данных с сервера, вызывать заданные хуки при приходе с сервера апдейтов, а также, в отличие от XDCR, делать merge конфликтующих документов самостоятельно написанным кодом;
- Касательно автофейловера не все так классно. Как уже отмечалось, нужно по крайней мере три ноды. Если Couchbase видит что-то, что похоже на одновременное падение более, чем одного узла, автофейловер ничего не делает. Так сделано, чтобы в случае нетсплита случайно не выбрать двух мастеров для одного vBucket’а. Тем не менее, если в результате нетсплита только один узел будет отделен от всего остального кластера, автофейловер все-таки сработает. После восстановления сети этот узел обнаружит, что имел место автофейловер, и грохонет все локальные изменения данных. Впрочем, все это не так уж страшно, если вы не держите в Couchbase ничего такого, что нельзя потом пересчитать, или если вы хотя бы делаете бэкапы;
К сожалению, рассмотреть Couchbase более подробно не представляется возможным в рамках одной заметки.
Заключение
В общем и целом система отличная. За час времени можно понять, что система из себя представляет, поднять кластер и начать им пользоваться. В плане скорости Couchbase оказался не хуже Memcached и Redis в ElastiCache , но при этом ощутимо дешевле. Дело в том, что в ElastiCache приходится платить отдельно за Memcached и отдельно за Redis, а Couchbase фактически предоставляет оба сервиса по цене одного. К сожалению, Couchbase из коробки не поддерживает работу с Set’ами и Map’ами, как это делает Redis, но их оказалось несложно реализовать самостоятельно поверх того, что есть. Были опасения, что придется много времени уделять мониторингу и прочей поддержке кластера, но в этом плане все оказалось очень, очень хорошо.
Не буду приводить конкретных цифр, которые я получил в результате своих бенчмарков, так как тут все сильно зависит от множества факторов . Но просто чтобы вы представляли порядок — при чтении и записи из/в Memcached bucket умным клиентом в 20 потоков с одной машины в кластер из трех m3.medium я видел стабильные 16.6к операций в секунду. Пинг внутри Амазона при этом составлял в районе 1.2 мс. Против 0.8 мс внутри DigitalOcean, против 0.3 мс между моим ноутом и домашним роутером по прямому соединению через витую пару. Так что, скорее всего, тупо упираемся в сеть: 20*1000/1.2 как раз получается 16.6к операций в секунду. Вероятно, имеет смысл рассмотреть размещение приложения и нод Couchbase кластера на одних и тех же машинах.
Ссылки по теме:
- Официальный сайт Couchbase ;
- Список рассылки couchbase@ в группах Google ;
- Тест Couchbase в стиле «Call Me Maybe», вроде ведет себя ОК ;
- Бенчмарк один , бенчмарк два , бенчмарк три [PDF] ;
- Никита Прокопов: Почему CouchBase — выдающийся piece of software ;
- Что нового будет в Couchbase 4.0 ;
А используете ли вы Couchbase, и если да, то каковы ваши впечатления от него? Особенно интересно было бы услышать об опыте использования репликации между дата-центрами.
Дополнение: Пара примеров работы с Couchbase на языке Scala