Обучение многослойного персептрона на примере логической операции XOR.
Обязательно изучите введение в нейронные сети .
В данном примере будем обучать нейронную сеть решать логическую операцию Xor. Xor имеет таблицу истинности.
| x1 | x2 | x1 xor x2 |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Чтобы решить данную задачу нужно будет создать многослойный персепрон следующего вида:
Перед тем как начать работу, установите одну из двух библиотек:
Решение для PyTorch
Проект perceptron-xor на гитхабе
Подключение библиотек и определение устройства, на котором будут выполняться вычисления:
_x000D_import torch_x000D_from torch import nn_x000D_from torchsummary import summary_x000D__x000D_# Detect device_x000D_tensor_device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') Подготовка обучающих данных
Перед тем, как начать обучать нейронную сеть, нужно создать обучающий набор данных и нормализировать его. Числа входного и выходного векторов должны быть в пределах от 0 до 1 включительно.
Определяем данные:
_x000D_data_train = [_x000D_ { "in": [0, 0], "out": [0] },_x000D_ { "in": [0, 1], "out": [1] },_x000D_ { "in": [1, 0], "out": [1] },_x000D_ { "in": [1, 1], "out": [0] },_x000D_]Это массив вопросов и правильных ответов. Обратите внимание, что входом и выходом являются вектора. Например, вход 2-мерный вектор (0, 0), выход 1-мерный вектор (0).
Сделаем две операции map, которые преобразуют массив data_train отдельно в массив вопросов и ответов. Массив вопросов будет состоять из значения поля «in». Массив ответов будет состоять из значений поля «out».
_x000D_# Convert to question and answer_x000D_tensor_train_x = list(map(lambda item: item["in"], data_train))_x000D_tensor_train_y = list(map(lambda item: item["out"], data_train))Преобразуем в тензор float32 на устройстве tensor_device.
_x000D_# Convert to tensor_x000D_tensor_train_x = torch.tensor(tensor_train_x).to(torch.float32).to(tensor_device)_x000D_tensor_train_y = torch.tensor(tensor_train_y).to(torch.float32).to(tensor_device)_x000D_Выведем на экран полученный результат:
_x000D_print ("Input:")_x000D_print (tensor_train_x)_x000D_print ("Shape:", tensor_train_x.shape)_x000D_print ("")_x000D_print ("Answers:")_x000D_print (tensor_train_y)_x000D_print ("Shape:", tensor_train_y.shape)Должно получится:
_x000D_Input:_x000D_tensor([[0., 0.],_x000D_ [0., 1.],_x000D_ [1., 0.],_x000D_ [1., 1.]], device='cuda:0')_x000D_Shape: torch.Size([4, 2])_x000D__x000D_Answers:_x000D_tensor([[0.],_x000D_ [1.],_x000D_ [1.],_x000D_ [0.]], device='cuda:0')_x000D_Shape: torch.Size([4, 1])Shape означается размерность вектора. Выражение (4, 2) означает, что дан массив из 4х 2-мерных векторов. Или другими словами двумерный массив с 4 строчками и 2 колонками.
На выходе получаем массив из 4х 1-мерных векторов. Обратите внимание, что количество строчек на входе и на выходе одинаковое и равно 4м. У нас в обучающей выборке 4 варианта вопросов и на каждый вопрос есть по одному ответу. В итоге на 4 вопроса, 4 ответа.
Данные подготовили. Сформировали два тензора вопросов и ответов, формата float32. Числа находятся в переделах от 0 до 1.
Можно приступать к созданию нейронной сети.
Создание модели нейронной сети
Архитектура нейронной сети будет следующая.
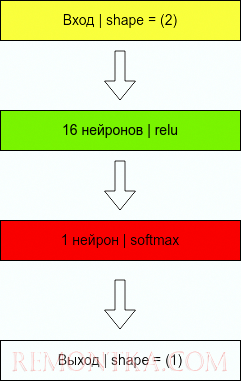
Почему такая? Опытным путем было выяснено, что другие архитектуры неработают. Создание архитектуры нейронной сети напоминает танец с бубном, когда нужно пробовать разные варианты, до тех пор, пока значение функции ошибки не станет минимальным.
Что можно менять:
- количество слоев.
- количество нейронов в слое.
- функции активации.
- функцию ошибки.
Методом тыка было выяснено, что архитектура нейронной сети должна состоять из 3х слоев.
- Входом в нейронную сеть будет являться 2-мерный вектор (x1,x2)
- Скрытый слой из 16 нейронов с функцией активации Relu.
- Выходной слой из одного нейрона с функцией активации Softmax. В большинстве случаев выход классификатора активируется функцией Softmax. Это важно!
- Выходом будет являться 1-мерный вектор, результат операции x1 xor x2
Создаем модель:
_x000D_input_shape = 2_x000D_output_shape = 1_x000D__x000D_model = nn.Sequential(_x000D_ nn.Linear(input_shape, 16),_x000D_ nn.ReLU(),_x000D_ nn.Linear(16, output_shape)_x000D_)_x000D__x000D_summary(model, (input_shape,))Параметры:
- Размер входного тензора input_shape — 2
- Размер выходного тензора output_shape — 1
- Количество нейронов на скрытом слое — 16
Зададим параметры оптимизации для модели:
_x000D_# Adam optimizer_x000D_optimizer = torch.optim.Adam(model.parameters(), lr=1e-3, betas=(0.9, 0.99))_x000D__x000D_# mean squared error_x000D_loss = nn.MSELoss()_x000D__x000D_# Batch size_x000D_batch_size = 2_x000D__x000D_# Epochs_x000D_epochs = 1000Параметры:
- Оптимизатор: Adam
- Функция ошибка: средне-квадратическая
Получается данная модель создает многослойный персептрон.
Выведем модель на экран:
_x000D_summary(model, (input_shape,))Результат выполнения команды:
_x000D_==========================================================================================_x000D_Layer (type:depth-idx) Output Shape Param #_x000D_==========================================================================================_x000D_├─Linear: 1-1 [-1, 16] 48_x000D_├─ReLU: 1-2 [-1, 16] --_x000D_├─Linear: 1-3 [-1, 1] 17_x000D_==========================================================================================_x000D_Total params: 65_x000D_Trainable params: 65_x000D_Non-trainable params: 0_x000D_Число 65 — это количество весов, которые будут в нейронной сети. Это число получается следующим образом:
- На входном слое 2 нейрона + 1 нейрон для bias. Итого 3 нейрона
- На скрытом слое 16 нейронов. Нужно (2 + 1) * 16 связей, чтобы соединить первый слой со вторым. Получаем число 48. Это число указано в графе параметр
- На выходном слое 1 нейрон. Его надо соединить с 16ю нейронами и одним bias нейроном. Итого нужно 17 связей
- Получаем всего нужно 48 + 17 = 65 связей и 65 весов для каждой связи.
Обучение нейронной сети
Обучение происходит через метод fit. Передаем в функцию вопросы и правильные ответы. Делаем 250 эпох по 4 обучения в каждой эпохе.
_x000D_history = []_x000D__x000D_# Переместим модель на устройство_x000D_model = model.to(tensor_device)_x000D__x000D_for i in range(epochs):_x000D_ _x000D_ # Вычислим результат модели_x000D_ model_res = model(tensor_train_x)_x000D_ _x000D_ # Найдем значение ошибки между ответом модели и правильными ответами_x000D_ loss_value = loss(model_res, tensor_train_y)_x000D_ _x000D_ # Добавим значение ошибки в историю, для дальнейшего отображения на графике_x000D_ loss_value_item = loss_value.item()_x000D_ history.append(loss_value_item)_x000D_ _x000D_ # Вычислим градиент_x000D_ optimizer.zero_grad()_x000D_ loss_value.backward()_x000D_ _x000D_ # Оптимизируем_x000D_ optimizer.step()_x000D_ _x000D_ # Остановим обучение, если ошибка меньше чем 0.01_x000D_ if loss_value_item < 0.01:_x000D_ break_x000D_ _x000D_ # Отладочная информация_x000D_ if i % 10 == 0:_x000D_ print (f"{i+1},t loss: {loss_value_item}")_x000D_ _x000D_ # Очистим кэш CUDA_x000D_ if torch.cuda.is_available():_x000D_ torch.cuda.empty_cache()Выведем красивый график. Это обязательно, чтобы понять правильно обучилась нейронная сеть или нет.
_x000D_import matplotlib.pyplot as plt_x000D__x000D_plt.plot(history)_x000D_plt.title('Loss')_x000D_plt.savefig('xor_torch.png')_x000D_plt.show() 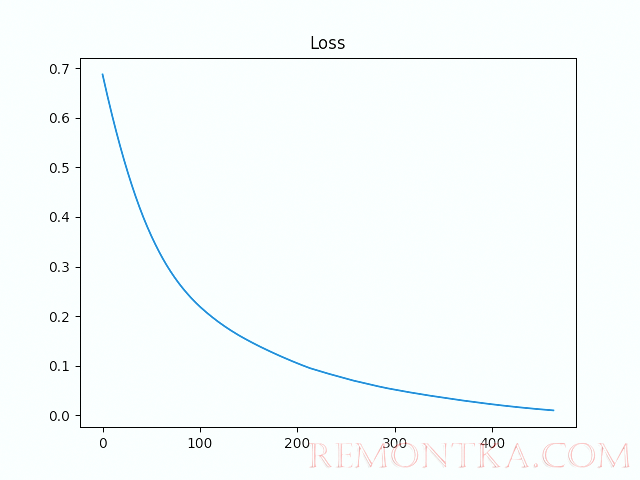
Как видно из графика, ошибка с каждой эпохи стремится к нулю. Делаем вывод, что нейронная сеть прошла обучение успешно.
Внедрение нейронной сети
Напишем небольшой тест для нейронной сети и проверим как она освоила операцию XOR.
_x000D_control_x = [_x000D_ [0, 0],_x000D_ [0, 1],_x000D_ [1, 0],_x000D_ [1, 1],_x000D_]_x000D__x000D_control_x = torch.tensor(control_x).to(torch.float32).to(tensor_device)_x000D__x000D_print ("Shape:", control_x.shape)_x000D__x000D_answer = model( control_x )_x000D__x000D_for i in range(len(answer)):_x000D_ print(control_x[i].tolist(), "->", answer[i].round().tolist())Выводит результат:
_x000D_Shape: torch.Size([4, 2])_x000D_[0.0, 0.0] -> [0.0]_x000D_[0.0, 1.0] -> [1.0]_x000D_[1.0, 0.0] -> [1.0]_x000D_[1.0, 1.0] -> [0.0]Видно, что нейронная сеть отвечает правильно.
Исходный код нейронной сети на TensorFlow
_x000D_#!/usr/bin/env python3_x000D_# -*- coding: utf-8 -*-_x000D__x000D_##_x000D_# Copyright (с) Ildar Bikmamatov 2022_x000D_# License: MIT_x000D_# Source:_x000D_# https://remontka.com/iskusstvennyj-intellekt/411-obuchenie-mnogoslojnogo-perseptrona-operaczii-xor_x000D_##_x000D__x000D_import numpy as np_x000D_import tensorflow as tf_x000D_import matplotlib.pyplot as plt_x000D_from tensorflow.keras.models import Sequential_x000D_from tensorflow.keras.layers import Dense, Input_x000D__x000D__x000D_# Step 1. Prepare DataSet_x000D_data_train = [_x000D_ { "in": [0, 0], "out": [0] },_x000D_ { "in": [0, 1], "out": [1] },_x000D_ { "in": [1, 0], "out": [1] },_x000D_ { "in": [1, 1], "out": [0] },_x000D_]_x000D__x000D__x000D_# Convert to question and answer DataSet_x000D_data_train_question = list(map(lambda item: item["in"], data_train))_x000D_data_train_answer = list(map(lambda item: item["out"], data_train))_x000D__x000D__x000D_# Normalize_x000D_data_train_question = np.array(data_train_question, "float32")_x000D_data_train_answer = np.array(data_train_answer, "float32")_x000D__x000D__x000D_# Print info_x000D_print ("Input:")_x000D_print (data_train_question)_x000D_print ("Shape:", data_train_question.shape)_x000D_print ("")_x000D_print ("Answers:")_x000D_print (data_train_answer)_x000D_print ("Shape:", data_train_answer.shape)_x000D__x000D_# Wait_x000D_print ("Press Enter to continue")_x000D_input()_x000D__x000D__x000D_# Step 2. Create tensorflow model_x000D_model = Sequential(name='XOR_Model')_x000D_model.add(Input(shape=(2), name='input'))_x000D_model.add(Dense(16, name='hidden', activation='relu'))_x000D_model.add(Dense(1, name='output', activation='softmax'))_x000D__x000D_# Compile_x000D_model.compile(loss='mean_squared_error', _x000D_ optimizer='adam',_x000D_ metrics=['accuracy'])_x000D_ _x000D_# Output model info to the screen _x000D_model.summary()_x000D__x000D_# Wait_x000D_print ("Press Enter to continue")_x000D_input()_x000D__x000D__x000D_# Step 3. Train model_x000D_history = model.fit(data_train_question, # Input_x000D_ data_train_answer, # Output_x000D_ batch_size=4,_x000D_ epochs=250,_x000D_ verbose=1)_x000D_ _x000D_plt.plot( np.multiply(history.history['accuracy'], 100), label='Correct answers')_x000D_plt.plot( np.multiply(history.history['loss'], 100), label='Error')_x000D_plt.ylabel('%')_x000D_plt.xlabel('Epochs')_x000D_plt.legend()_x000D_plt.savefig('xor_model.png')_x000D_plt.show()_x000D__x000D__x000D_# Step 3. Test model_x000D_test = [_x000D_ [0, 0],_x000D_ [0, 1],_x000D_ [1, 0],_x000D_ [1, 1],_x000D_]_x000D__x000D_test = np.asarray(test)_x000D__x000D_print ("Shape:", test.shape)_x000D__x000D_answer = model.predict( test )_x000D__x000D_for i in range(0,len(answer)):_x000D_ print(test[i], "->", answer[i].round())_x000D_