Мне захотелось попробовать разные программы для Микроши . В наши дни они распространяются в виде файлов RKM. Существуют готовые конвертеры из RKM в аудио, но они имеют различные проблемы. Например, WRKWIN32.EXE как будто работает, но мой Микроша отказывается загружать результирующее аудио. То ли не та версия Wine, то ли не та звуковая карта — об истинной причине остается лишь гадать. В общем, долго ли, коротко ли, было решено написать свой конвертер.
С WAV-файлами мне доводилось работать ранее ( раз , два ), поэтому здесь проблем не предвиделось. Однако формат файлов RKM мне не был знаком. Также я не знал, каким именно образом Микроша сохраняет данные на кассетах. Разобраться в этих вопросах помогла статья Создание демки специально для HABR, Часть 1 и ссылки из нее, в особенности исходники утилиты bin2wav .
Формат RKM оказался простым:
——————————————————————-
addr_start 2 байта Начальный адрес в big-endian
addr_end 2 байта Конечный адрес в big-endian
data переменный (addr_end — addr_start + 1) байт данных
checksum 2 байта Контрольная сумма в big-endian
Обратите внимание, что данные хранятся с addr_start по addr_end включительно.
На кассете используется уже знакомое нам манчестерское кодирование :
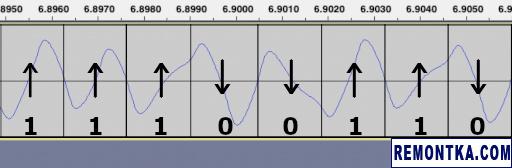
Этот метод также называется двухфазным кодированием. Есть заранее заданная скорость кодирования информации. Для Микроши она составляет 700 бит/сек. Аудио нарезается на отрезки соответствующей длины. Если на отрезке задний фронт (спад) сигнала, то это ноль, а если передний фронт — это единица.
В байте кодируются сначала старшие биты, затем младшие. Слова кодируются в порядке байт от старших к младшим, то есть, в big-endian. Тут главное не запутаться при написании конвертера. В формате WAV, к примеру, все наоборот, используется little-endian.
Формат данных на кассете оказался таким:
——————————————————————-
preamble 256 байт Нулевые байты
sync 1 байт Байт синхронизации 0xE6
addr_start 2 байта Начальный адрес
addr_end 2 байта Конечный адрес
data переменный (addr_end — addr_start + 1) байт данных
checksum 2 байта Контрольная сумма
Конвертер было решено писать на Python , потому что он не требует компиляции и работает везде. Значит, воспользоваться конвертером смогут все желающие.
Хотите верьте, хотите нет, но работать с бинарными файлами на Python мне ранее не доводилось. Впрочем, это оказалось не сложно. Вот пример чтения:
# чтение 16-и битного слова в big-endian
addr_start = int . from_bytes ( fin. read ( 2 ) , ‘big’ )
# чтение одного байта
next_byte = int . from_bytes ( fin. read ( 1 ) , ‘big’ )
А вот пример записи:
# запись типа bytes
fout. write ( b ‘ x 01 x 02 x 03′ )
# то же самое на списках
fout. write ( bytes ( [ 1 , 2 , 3 ) )
Поначалу скрипт тестировался с эмулятором Emu80 . На эмуляторе загружать сконвертированные файлы получилось довольно быстро. На этом этапе я знал, что нигде не ошибся с порядком бит или байт, а также что данные, скорее всего, правильно кодируются в WAV-файле. Однако, ситуацию омрачал тот факт, что конвертер работал только с эмулятором, но не с реальным железом.
Понимание проблемы заняло некоторое время. В ходе внимательного сравнения в Audacity моих WAV-файлов с записями, полученными в результате оцифровки кассеты, было найдено лишь одно отличие. Файлы, которые выдавал конвертер, содержали «прямоугольные» сигналы, с резкими фронтами, тогда как на кассете сигналы имели сглаженные фронты. Было решено применить к моим файлам ФНЧ и посмотреть, что будет.
Форма сигнала до и после:
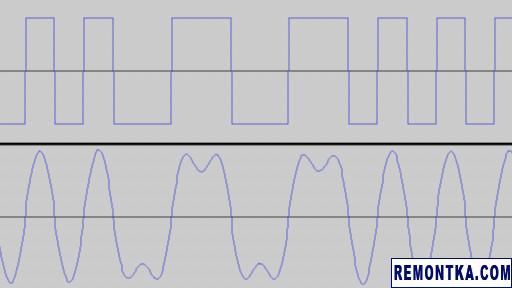
К моей радости, отфильтрованный сигнал был успешно обработан Микрошей. Выходит, что проблема заключалась только в резких фронтах. Я не был уверен в истинных причинах такого поведения и обратился за советом в Telegram. Наиболее правдоподобное, на мой взгляд, объяснение предложил GoodLoki: «Резкие фронты в реальной цепи могут создавать слишком большие пики на переходном процессе, которые будут порождать фальшивые фронты и спады».
Получить сглаженный сигнал можно разными способами. Например, можно в правильном порядке склеивать заранее сглаженные куски аудио. Моей первый мыслью было пойти самым простым путем и считать бегущее среднее. Но быстро выяснилось, что для получения красивой формы сигнала, как в Audacity, нужно подбирать весовые коэффициенты. Фактически, получается FIR-фильтр . Ну раз такое дело, было решено использовать полноценный FIR-фильтр. (Технически, бегущее среднее и есть частный случай FIR-фильтра.)
Коэффициенты фильтра были получены при помощи замечательного онлайн-калькулятора fiiir.com , который разработал Tom Roelandts . Существует похожий калькулятор t-filter.engineerjs.com . Как оказалось, тот факт, что фронты в сигнале как-то сглажены, еще не значит, что Микроша сможет его переварить. Поэтому фильтр пришлось подбирать.
Дополнение: Также DSP-фильтры могут быть рассчитаны при помощи SciPy .
В итоге был использован такой:
Sampling rate [Hz]: 44100
Cutoff frequency [Hz]: 1600
Transition bandwidth [Hz]: 2200
Window type: Hamming
Фильтру требуется 63 коэффициента. Его реализация на Python такова:
0.000577926080672738 ,
0.000459465018502213 ,
# … и так далее, всего 63 штуки …
]
WINDOW_SIZE = len ( FIR_WEIGHTS )
fir_window = [ 128 for i in range ( 0 , WINDOW_SIZE ) ]
def fir_low_pass_filter ( arr ) :
global fir_window , FIR_WEIGHTS
res = [ ]
for i in range ( 0 , len ( arr ) ) :
fir_window = [ arr [ i ] ] + fir_window [ 0 :WINDOW_SIZE- 1 ]
filtered = int ( sum ( [ fir_window [ j ] * FIR_WEIGHTS [ j ]
for j in range ( 0 , WINDOW_SIZE ) ] ) )
res + = [ filtered ]
return res
Тут следует учесть, что скрипт генерирует 8-и битные WAV-файлы, в которых 0 соответствует минимальному уровню сигнала, 255 — максимальному уровню, а 128 — нулевому уровню. Так как сигнал выходит из фильтра с задержкой, по окончании конвертации нужно прогнать через фильтр немного тишины:
fout. write ( bytes ( fir_low_pass_filter ( silence ) ) )
file_size + = WINDOW_SIZE
В остальном же работа скрипта тривиальна, поэтому я не вижу смысла разбирать ее более подробно. Полную версию можно скачать здесь .
Большие программы вроде Шахмат на моем железе скрипт переваривает до одной минуты. Небольшие, вроде Тетриса или Сокобана, занимают порядка 10 секунду. Больше всего времени уходит на фильтрацию. Не быстро, но жить можно. Заинтересованным читателям предлагается произвести оптимизацию программы в качестве упражнения. Если же такая задача вам не интересна, предлагаю написать обратный конвертер из WAV в RKM.
Дополнение: С оптимизацией скрипта первым справился @kimstik . Теперь любой RKM файл конвертируется менее, чем за секунду. Оптимизированную версию можно скачать здесь .