Что такое поисковые системы? Как работают поисковые системы? Ответы на эти вопросы вы найдете здесь.
Что такое поисковик?
По определению, интернет-поисковик это система поиска информации, которая помогает нам найти информацию во всемирной паутине. Это облегчает глобальный обмен информацией. Но интернет является неструктурированной базой данных. Он растет в геометрической прогрессии, и стал огромным хранилищем информации. Поиск информации в интернете, является трудной задачей. Существует необходимость иметь инструмент для управления, фильтра и извлечения этой океанической информации. Поисковая система служит для этой цели.
Как работает поисковая система?
Поисковые системы интернета являются двигателями, поиска и извлечения информации в интернете. Большинство из них используют гусеничную архитектуру индексатора. Они зависят от их гусеничных модулей. Сканеры также называют пауками это небольшие программы, которые просматривают веб-страницы.
Сканеры посещают первоначальный набор URL-адресов. Они добывают URL-адреса, которые появляются на просканированных страницах и отправляют эту информацию в модуль гусеничный управления. Гусеничный модуль решает, какие страницы посетить в следующий раз и дает эти URL-адреса сканерам.
Темы, охватываемые различными поисковыми системами, варьируются в зависимости от алгоритмов, которые они используют. Некоторые поисковые системы запрограммированы на поисковые сайты по конкретной теме, в то время как сканеры других могут посещать столько мест, сколько возможно.
Модуль управления может использовать ссылки предыдущего сканирования или шаблоны, чтобы помочь в стратегии сканирования.
Модуль индексации извлекает информацию из каждой страницы, которую он посещает и вносит URL в базу. Это приводит к образованию огромной таблицы поиска, из списка URL-адресов указывающих на страницы с информацией. В таблице приведены те страницы, которые были покрыты в процессе обхода.
Модуль анализа является еще одной важной частью архитектуры поисковой системы. Он создает индекс полезности. Индекс утилита может предоставить доступ к страницам заданной длины или страниц, содержащих определенное количество картинок на них.
В процессе сканирования и индексирования, поисковик сохраняет страницы, которые он извлекает. Они временно хранятся в хранилище страницы. Поисковые системы поддерживают кэш страниц которые они посещают, чтобы ускорить извлечение уже посещенных страниц.
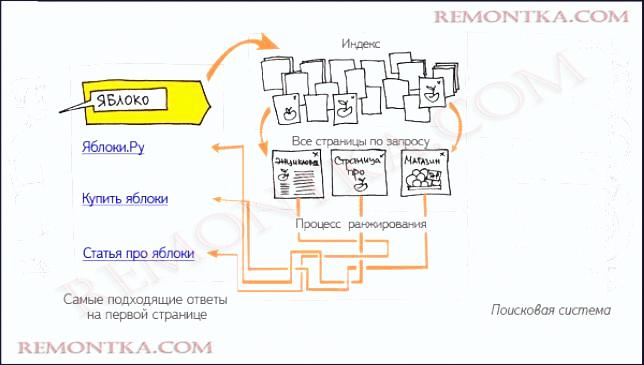
Модуль запроса поисковой системы получает поисковый запросов от пользователей в виде ключевых слов. Модуль ранжирования сортирует результаты.
Архитектура гусеничного индексатора имеет много вариантов. Они изменяются в распределенной архитектуре поисковой системы. Эти архитектуры состоят из собирателей и брокеров. Собиратели собирают информацию индексации с веб-серверов в то время как брокеры дают механизм индексирования и интерфейс запросов. Брокеры индексируют обновление на основе информации, полученной от собирателей и других брокеров. Они могут фильтровать информацию. Многие поисковые системы сегодня используют этот тип архитектуры.
Поисковые системы и ранжирования страниц
Когда мы создаем запрос в поисковой системе, результаты отображаются в определенном порядке. Большинство из нас, как правило, посещают страницы верхнего порядка и игнорируют последние. Это потому, что мы считаем, что верхние несколько страниц несут большую актуальность для нашего запроса. Так что все заинтересованы в рейтинге своих страниц в первых десяти результатов в поисковой системе.
Слова, указанные в интерфейсе запроса поисковой системы являются ключевыми словами, которые запрашивались в поисковых системах. Они представляют собой список страниц, имеющих отношение к запрашиваемым ключевым словам. Во время этого процесса, поисковые системы извлекают те страницы, которые имеют частые вхождений этих ключевых слов. Они ищут взаимосвязи между ключевыми словами. Расположение ключевых слов также считается, как и рейтинг страницы, содержащие их. Ключевые слова, которые встречаются в заголовках страниц или в URL, приведены в больший вес. Страницы, имеющие ссылки, указывающие на них, делают их еще более популярными. Если многие другие сайты, ссылаются на какую либо страницу, она рассматривается как ценная и более актуальная.
Существует алгоритм ранжирования, который использует каждая поисковая система. Алгоритм представляет собой компьютеризированную формулу разработанную, чтобы предоставлять соответствующие страницы по запросу пользователя. Каждая поисковая система может иметь различный алгоритм ранжирования, который анализирует страницы в базе данных двигателя, чтобы определить соответствующие ответы на поисковые запросы. Различные сведения поисковые системы индексируют по-разному. Это приводит к тому, что конкретный запрос, поставленный двум различным поисковым машинам, может принести страницы в различных порядках или извлечь разные страницы. Популярность веб-сайта являются факторами, определяющими актуальность. Клик-через популярность сайта является еще одним фактором, определяющим его ранг. Это мера того, насколько часто посещают сайт.
Веб-мастера пытаются обмануть алгоритмы поисковой системы, чтобы поднять позиции своего сайта в поисковой выдаче. Заполняют страницы сайта ключевыми словами или используют мета теги, чтобы обмануть стратегии рейтинга поисковой системы. Но поисковые системы достаточно умны! Они совершенствуют свои алгоритмы так, чтобы махинации веб-мастеров не влияли на поисковую выдачу.
Нужно понимать, что даже страницы после первых нескольких в списке могут содержать именно ту информацию, которую вы искали. Но будьте уверены, что хорошие поисковые системы всегда принесут вам высоко релевантные страницы в верхнем порядке!